
Além de serem dispositivos críticos para a funcionalidade do sistema, são os dispositivos de armazenamento HDs e SSDs que contém muitas de nossas informações mais preciosas. São eles também geralmente os dispositivos mais exigidos pelo sistema e, apesar da alta durabilidade, é sempre muito importante estar ciente a respeito de suas respectivas integridades para não termos surpresas e perdas significativas.
É por isso, inclusive, que os discos rígidos (HDs) e as unidades de estado sólido (SSDs) vêm com a tecnologia S.M.A.R.T. cuja sigla diz respeito a Self-Monitoring, Analysis, and Reporting Technology, que, na tradução para o português do Brasil, diz respeito a tecnologia de automonitoramento, análise e relatório. Essa tecnologia consiste num sistema eficiente de monitoramento capaz de detectar e informar a respeito de vários indicadores de confiabilidade da unidade, com o fim de permitir a antecipação de uma eventual falha de hardware.
Portanto, neste tutorial, vamos acessar, visualizar e entender esses dados, de modo que possamos visualizar com destaque a saúde principal de nosso dispositivo. Isso será feito com o leve software CrystalDiskInfo que é perfeitamente capaz de acessar, interpretar e nos disponibilizar as informações de modo claro e compreensível.
Passo 1: Baixe o CrystalDiskInfo por meio deste link e realize a instalação do programa no seu computador.
Passo 2: Após instalado, abra a interface do programa por meio do atalho gerado em sua área de trabalho e localize o termo “Status de Saúde”, conforme a captura de tela abaixo. Note que ele também é capaz de diagnosticar HDs externos.
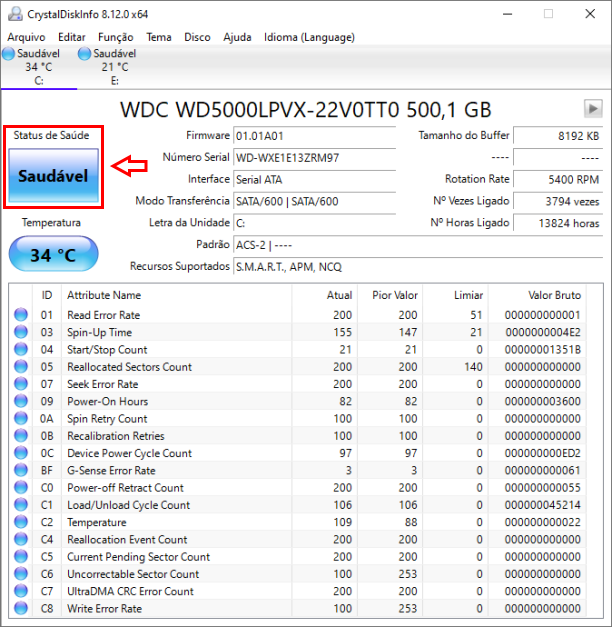
Observação: Em “Status de Saúde” podem, conforme documentação do desenvolvedor, vir quatro tipos de informações: “Saudável” que diz respeito a um dispositivo em perfeitas condições, “Alerta” que pode significar um dispositivo próximo do final de sua vida útil, entretanto deve ser interpretado conforme os setores que apresentam o alerta, “Crítico” que diz respeito a um dispositivo em uma condição ruim e que possa parar de funcionar a qualquer momento e, por fim, “Desconhecido” que diz respeito a quando o sistema S.M.A.R.T. não estiver disponível ou acessível.
Observação 2: A lista de atributos S.M.A.R.T. pode variar conforme o dispositivo e o fabricante, porém, abaixo, serão listados alguns dos mais importantes atributos a se relevar, onde os considerados críticos são os em vermelho. As informações foram extraídas deste artigo da Wikipedia no qual você pode tê-las de modo mais amplo para todo e qualquer dispositivo.
- Read Error Rate: Armazena dados relacionados à taxa de erros de leitura de hardware que ocorreram durante a leitura de dados de uma superfície de disco. O valor bruto tem uma estrutura diferente para diferentes fornecedores e geralmente não é significativo como um número decimal. Para algumas unidades, esse número pode aumentar durante a operação normal, sem necessariamente significar erros.
- Spin-Up Time: Tempo médio de rotação do fuso (de zero RPM até totalmente operacional [milissegundos]).
- Start/Stop Count: Uma contagem dos ciclos de partida / parada do fuso. O fuso é ligado e, portanto, a contagem é aumentada, tanto quando o disco rígido é ligado depois de ter sido antes totalmente desligado (desconectado da fonte de alimentação) e quando o disco rígido retorna após ter sido colocado no modo de hibernação.
- Reallocated Sectors Count: Contagem de setores realocados. O valor bruto representa uma contagem dos setores defeituosos que foram encontrados e remapeados. Portanto, quanto maior o valor do atributo, mais setores a unidade teve que realocar. Esse valor é usado principalmente como uma métrica da expectativa de vida da unidade; uma unidade que teve qualquer realocação tem significativamente mais probabilidade de falhar nos meses imediatos.
- Seek Error Rate: Taxa de erros de busca das cabeças magnéticas. Se houver uma falha parcial no sistema de posicionamento mecânico, surgirão erros de busca. Essa falha pode ser devido a vários fatores, como danos a um servo ou alargamento térmico do disco rígido. O valor bruto tem uma estrutura diferente para diferentes fornecedores e geralmente não é significativo como um número decimal. Para algumas unidades, esse número pode aumentar durante a operação normal, sem necessariamente significar erros.
- Power-On Hours: Contagem de horas no estado ligado. O valor bruto deste atributo mostra a contagem total de horas (ou minutos ou segundos, dependendo do fabricante) no estado de inicialização. “Por padrão, a vida útil total esperada de um disco rígido em perfeitas condições é definida como 5 anos (executando todos os dias e todas as noites). Isso é igual a 1.825 dias no modo 24/7 ou 43.800 horas.
- Spin Retry Count: Contagem de novas tentativas de tentativas de início de rotação. Este atributo armazena uma contagem total de tentativas de início de rotação para atingir a velocidade operacional total (sob a condição de que a primeira tentativa não foi bem-sucedida). Um aumento neste valor de atributo é um sinal de problemas no subsistema mecânico do disco rígido.
- End-to-End error / IOEDC: Este atributo é parte da tecnologia SMART IV da Hewlett-Packard e também faz parte dos esquemas de detecção e correção de erros de outros fornecedores. Trata-se da contagem de erros de paridade que ocorrem no caminho de dados para a mídia por meio da unidade cache de RAM.
- Reported Uncorrectable Errors: A contagem de erros que não puderam ser recuperados usando o ECC de hardware.
- Hardware ECC Recovered: O valor bruto tem uma estrutura diferente para diferentes fornecedores e geralmente não é significativo como um número decimal. Para algumas unidades, esse número pode aumentar durante a operação normal, sem necessariamente significar erros.
- Command Timeout: A contagem de operações canceladas devido ao tempo limite do HD. Normalmente, este valor de atributo deve ser igual a zero.
- Temperature: A temperatura real do dispositivo é exibida abaixo do status de saúde. O valor da tabela é um valor que permite que o fabricante defina um limite mínimo que corresponde a uma temperatura máxima. Isso também segue a convenção de 100 sendo um valor de melhor caso e valores mais baixos sendo indesejáveis. No entanto, algumas unidades mais antigas podem relatar temperatura bruta (idêntica a 0xC2) ou temperatura menos 50 aqui.
- Reallocation Event Count: Contagem de operações de remapeamento. O valor bruto deste atributo mostra a contagem total de tentativas de transferência de dados de setores realocados para uma área sobressalente. As tentativas bem-sucedidas e malsucedidas são contadas.
- Current Pending Sector Count: Contagem de setores “instáveis” (esperando para serem remapeados, devido a erros de leitura irrecuperáveis). Se um setor instável for subsequentemente lido com sucesso, o setor será remapeado e esse valor será diminuído. Erros de leitura em um setor não remapearão o setor imediatamente (uma vez que o valor correto não pode ser lido e, portanto, o valor a ser remapeado não é conhecido e também pode se tornar legível posteriormente); em vez disso, o firmware da unidade lembra que o setor precisa ser remapeado e o remapeia na próxima vez que for gravado. No entanto, algumas unidades não remapearão imediatamente esses setores quando gravados; em vez disso, a unidade tentará primeiro gravar no setor com problema e, se a operação de gravação for bem-sucedida, o setor será marcado como bom (neste caso, a “Contagem de eventos de realocação” (0xC4) não será aumentada). Esta é uma deficiência séria, pois se tal unidade contiver setores marginais que falham consistentemente somente após algum tempo após uma operação de gravação bem-sucedida, a unidade nunca remapeará esses setores problemáticos.
- Uncorrectable Sector Count: A contagem total de erros incorrigíveis ao ler / gravar um setor. Um aumento no valor deste atributo indica defeitos da superfície do disco e / ou problemas no subsistema mecânico.
- UltraDMA CRC Error Count: A contagem de erros na transferência de dados por meio do cabo de interface, conforme determinado pelo ICRC (Verificação de redundância cíclica de interface).
- Write Error Rate: contagem total de erros ao gravar um setor.
- Soft Read Error Rate ou TA Counter Detected: Contagem que indica o número de erros de leitura de software incorrigíveis.
{kind=link}
Valeu!!!!